










了解当今运营团队面临的核心挑战
现代运营团队在复杂的迷宫中穿梭。您需要应对随叫随到轮班、响应关键事件并管理不断增长的基础设施。这种辛劳是真实存在的,导致倦怠和被动工作。
考虑以下常见的痛点:
- 工具碎片化:在无数的应用程序之间切换,用于监控、警报和部署,浪费了宝贵的时间。
- 手动过载:重复性任务耗费了数小时,而这些时间本可以用于战略性举措。
- 信息孤立:数据分散在各个系统中,使根本原因分析成为一场噩梦,阻碍了有效的业务运营。
- 事件响应缓慢:检测和解决的延迟直接影响用户体验和收入。
这些挑战阻碍了团队实现真正的效率并限制了其创新能力。
Lovable.dev 简介:运营领域的颠覆者
告别运营难题,迎接效率新时代。Lovable.dev for Ops 重新构想了运营管理的工作方式。我们提供一个统一的平台,旨在简化您最关键的工作流程,减少繁重工作,并加速您达到卓越性能的路径。
我们的平台不仅仅是另一个工具;它是您运营的战略合作伙伴。通过将智能和自动化置于首位,Lovable.dev 将您的日常繁琐工作转变为富有成效、积极主动的体验。准备好体验真正强大而令人愉悦的简单运营吧。
我们的平台不仅仅是另一个工具;它是您运营的战略合作伙伴。通过将智能和自动化置于首位,Lovable.dev 将您的日常繁琐工作转变为富有成效、积极主动的体验。准备好体验真正强大而令人愉悦的简单运营吧。

现代 SRE 实践的基本功能
实现顶级的站点可靠性工程不仅仅需要良好的意图。它需要一个强大的工具包。Lovable.dev for Ops 正是提供了这一点,将关键功能整合到一个统一、有凝聚力的平台中。
我们的基本功能赋能您的 SRE 团队:
- 智能警报:通过智能关联和路由,接收可操作的通知,而不仅仅是噪音。
- 自动化修复:针对常见问题触发预定义操作,在问题升级之前解决它们。
- 服务水平目标 (SLO) 跟踪:轻松定义、监控和报告关键可靠性目标。
- 无责事后分析工具:在每次事件后促进全面的分析和学习,推动持续改进。
这些功能帮助您从被动救火转向主动、数据驱动的可靠性管理,从而改善整体运营管理。
提升站点可靠性工程
站点可靠性工程(SRE)的成功离不开数据、自动化和持续改进的文化。Lovable.dev for Ops 为真正的卓越提供了基础设施。我们帮助您的团队超越“维持系统运行”的简单层面,积极提升系统健康和性能。
我们如何提升您的 SRE:
我们赋能 SRE 专注于工程解决方案,而非手动任务。我们的平台有助于减少平均恢复时间 (MTTR),最大程度地减少服务中断,并最终构建更具弹性的系统。这意味着将更多时间用于战略性工作,更少时间用于重复的救火。
我们赋能 SRE 专注于工程解决方案,而非手动任务。我们的平台有助于减少平均恢复时间 (MTTR),最大程度地减少服务中断,并最终构建更具弹性的系统。这意味着将更多时间用于战略性工作,更少时间用于重复的救火。
实现更高的 SLO 达成率和更稳定的环境,使您的运营管理变得主动而强大。
无缝事件管理和解决
当事件发生时,每一秒都至关重要。Lovable.dev for Ops 提供了一个统一的事件管理指挥中心,将混乱转变为受控的解决方案。我们的平台确保清晰的沟通、快速诊断和高效的团队协作。
以下是我们如何简化您的事件工作流程:
- 自动化检测:与您的监控工具集成,即时检测异常并触发事件。
- 智能路由:根据定义的排班和服务所有权,确保正确的待命人员收到警报。
- 协作工作区:将所有相关团队成员和数据集中到一个虚拟作战室中。
- 事件后分析:自动捕获关键数据,用于全面的无责事后分析和学习。
通过强大的事件响应工作流程自动化,加快诊断,改善协调,并减少中断的影响。
提升可观测性和监控能力
你无法修复你看不见的东西。Lovable.dev for Ops 为您的系统提供无与伦比的可见性,将原始数据转化为可操作的洞察。我们将各种数据源——指标、日志、追踪——整合到一个直观的视图中,从而增强您的运营管理。
我们的平台提供:
- 统一仪表盘:在一个地方可视化您的整个基础设施和应用程序的健康状况和性能。
- 上下文丰富的警报:收到包含所有相关上下文的警报,帮助您快速理解问题。
- 深入分析:深入钻研特定问题,关联跨服务的事件,并更快地找出根本原因。
- 预测分析:在潜在问题影响用户之前识别它们,利用高级效率工具。
全面了解您的业务运营并主动解决性能瓶颈。
自动化关键运营工作流程
手动运营任务耗时、易出错,并耗尽团队精力。Lovable.dev for Ops 倡导智能工作流程自动化,为您减轻重负。我们将重复性程序转化为可靠的自动化流程。
想象一下自动化以下内容:
常见修复
响应特定警报,自动重启服务、清除缓存或扩展资源。
部署发布
通过内置检查和回滚功能,编排复杂的部署序列。
入职流程
自动化新环境或用户权限的设置,确保一致性。
计划维护
无需人工干预即可执行日志轮换或数据库清理等日常任务。
让您的运营团队专注于战略性工作、创新和复杂的问题解决。通过智能自动化实现真正的运营效率。
通过平台工程赋能开发者体验
蓬勃发展的开发者体验对于快速创新至关重要。Lovable.dev for Ops 在平台工程中发挥着关键作用,使运营团队能够为开发者提供自助服务功能和标准化环境。这加速了开发周期并促进了协作。
我们通过以下方式赋能开发者:
- 为常见运营任务提供自助服务门户,减少工单疲劳。
- 确保一致、经过实战检验的基础设施设置。
- 提供对服务健康和依赖项的清晰可见性。
- 通过自动化防护措施简化部署管道。
当开发者能够轻松访问所需资源并自信地进行部署时,创新就会蓬勃发展,直接影响业务运营。
与您现有的技术堆栈集成
我们理解您已经拥有一个工具生态系统。Lovable.dev for Ops 的目的不是取代所有工具;它旨在实现无缝集成。我们开放的、API优先的方法确保您可以轻松连接您最喜欢的监控、警报、SCM 和协作平台。
关键集成优势:
| 集成重点 | Lovable.dev 如何帮助 |
|---|---|
| 监控与警报 | 摄取来自 Prometheus、Grafana、Datadog 等的警报,实现统一事件管理。 |
| 通讯 | 在 Slack、Microsoft Teams 或 PagerDuty 中发送通知并促进协作。 |
| 版本控制 | 连接到 GitHub、GitLab、Bitbucket,实现工作流程自动化和配置管理。 |
| 云提供商 | 管理来自 AWS、Azure、GCP 和 Kubernetes 的资源并收集数据。 |
利用您当前的投资,同时通过智能连接解锁更高水平的运营效率。
优化性能和资源利用率
低效的资源使用会造成资金浪费并阻碍性能。Lovable.dev for Ops 帮助您深入了解基础设施和应用程序的资源消耗情况,从而实现更智能的分配并显著节省成本。这是有效运营管理的核心组成部分。
我们的平台使您能够:
- 识别您的云和本地环境中未充分利用的资源。
- 在性能瓶颈影响用户之前发现它们。
- 根据实时需求实施自动化扩展策略。
- 分析历史使用模式,为未来的容量规划提供信息。
事半功倍,确保您的系统以最佳状态运行,并且您的预算得到更充分的利用。这些是现代业务运营中至关重要的效率工具。
确保运营中的安全性和合规性
在现代运营中,安全性和合规性是不可协商的。Lovable.dev for Ops 将强大的安全功能和审计能力直接嵌入到您的运营工作流程中,帮助您满足法规要求并保护敏感数据。强大的安全性是有效运营管理的基础。
我们帮助您保持安全和合规的态势:
“安全性并非一项功能;它是良好管理运营的结果。Lovable.dev 提供了将安全检查和合规性保障措施直接嵌入您的日常工作流程的工具。”
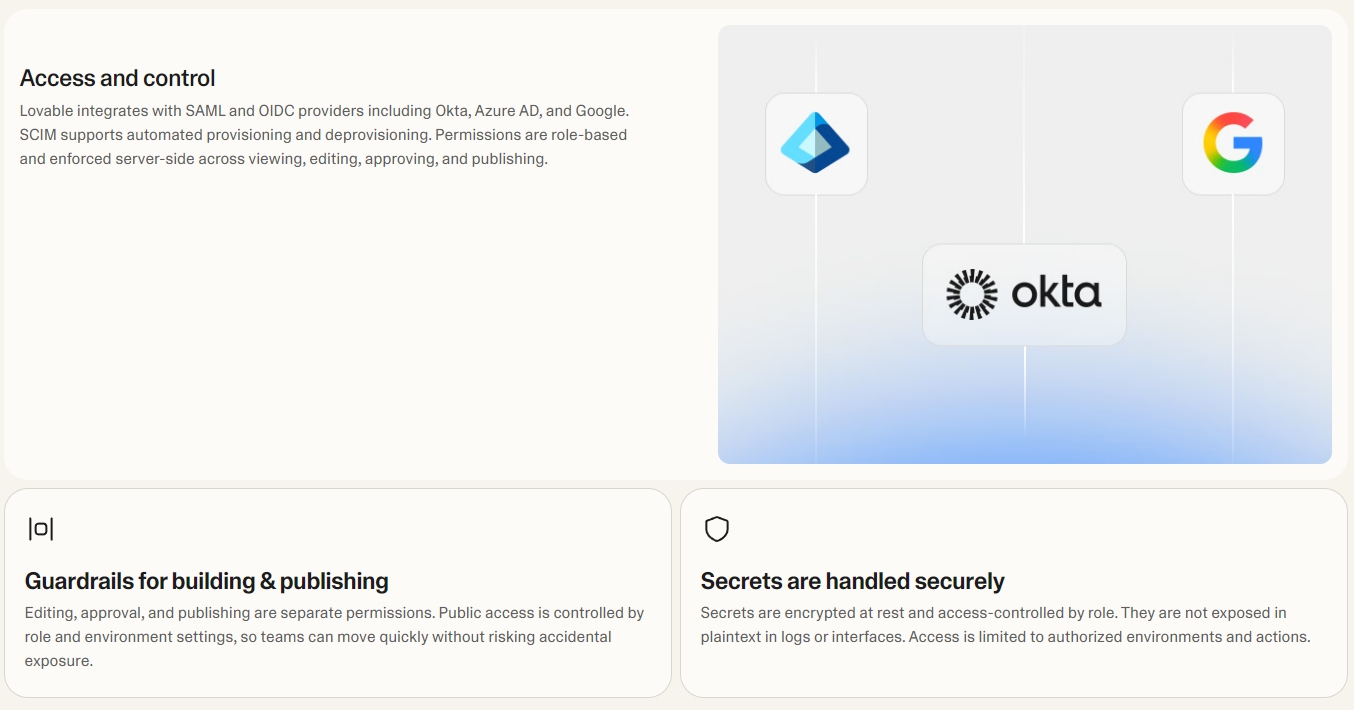
- 访问控制:对运营工具和数据进行精细的角色基于访问控制。
- 审计追踪:全面记录所有操作,以便进行问责和合规性审计。
- 配置管理:通过自动化策略,在您的基础设施中强制执行安全最佳实践。
- 漏洞扫描:与安全扫描工具集成,实现持续监控。
自信地操作,因为您知道您的关键系统受到保护并符合规定。
扩展您的运营效率
随着组织的发展,您的运营复杂性不应失控。Lovable.dev for Ops 专为规模化而构建。无论您管理少数服务还是数千项服务,我们的平台都能确保您的运营保持高效、可管理且高性能。这是针对扩展业务运营的真正工作流程自动化。
我们如何支持您的增长:
- 集中管理
- 无论服务数量多少,都可以通过单一控制面板监督您的所有服务、团队和环境。
- 标准化工作流程
- 在所有团队中强制执行一致的运营实践,减少差异和错误。
- 自动化配置
- 随着需求的增加,快速配置新的资源和服务,而不会出现手动瓶颈。
- 规模化性能
- 我们平台的架构旨在处理大量数据和复杂的自动化而不会降低性能。
扩展您的业务版图,而无需增加烦恼。自信地扩展您的运营管理。
运营专业人员的实际用例
Lovable.dev for Ops 如何为您的团队带来实际益处?让我们看看我们的平台在实际场景中如何提供即时价值,展示真正的运营管理。
以下是运营专业人员利用 Lovable.dev 的几种方式:
- 自动化服务重启:配置警报,在关键组件出现故障时自动触发服务重启,通常在任何人注意到之前解决问题。
- 待命交接简化:生成正在进行的事件和系统健康状况的全面摘要,实现班次之间的无缝过渡。
- 部署审批工作流程:为关键部署实施自动化检查和人工审批步骤,降低发布风险。
- 资源清理自动化:安排任务以识别和删除云环境中过时的资源,优化成本。
- 审计日志生成:自动编译详细的审计追踪以用于合规性报告,节省大量手动工作。
这些示例说明了工作流程自动化如何将日常任务转化为高效、可靠的流程。
您的平台实施指南
采用新技术应该令人兴奋,而不是令人望而生畏。我们使实施 Lovable.dev for Ops 变得简单而支持性。我们的目标是让您的团队快速启动并运行,从第一天起就为您的运营管理实现价值。
我们的实施旅程通常包括以下步骤:
- 初步探索:我们与您的团队合作,了解您当前的挑战和集成需求。
- 配置与集成:将 Lovable.dev 与您现有的监控、SCM 和通信工具连接。
- 工作流程设计:协作定义并自动化您的第一个关键运营工作流程。
- 团队培训:全面的培训课程确保您的运营专业人员能够充分利用平台的强大功能。
- 持续支持:获取我们专家支持团队的帮助,解决任何问题或进行高级配置。
今天就开始您的真正令人愉悦的运营之旅。让我们用这些强大的效率工具引导您走向卓越运营。
展望运营的未来
想象一个运营世界,其中繁琐的工作最小化,事件稀少,创新蓬勃发展。这并非痴心妄想;这是 Lovable.dev for Ops 帮助您构建的未来。我们设想一个运营团队成为战略合作伙伴的局面,推动业务增长,而不是不断地应对问题。
在运营管理的这个未来中:
- 系统是自修复的,能够自主预测和解决问题。
- 团队轻松协作,分享见解并加速解决方案。
- 数据驱动的决策带来持续改进和主动可靠性。
- 卓越运营成为竞争优势,吸引顶尖人才并提升客户满意度。
与我们一起塑造这个未来。拥抱主动的工作流程自动化,提升您的站点可靠性工程,让您的运营真正令人喜爱。现在是时候进行转型了。
常见问题
Lovable.dev for Ops 是什么?
Lovable.dev for Ops 是一个统一平台,旨在简化关键运营工作流程,减少繁重工作,并加速团队达到站点可靠性工程 (SRE) 的卓越性能。它通过智能和自动化重新构想运营管理,使其主动且强大。
Lovable.dev 如何解决运营团队的常见挑战?
Lovable.dev 解决工具碎片化、手动过载、信息孤立和事件响应缓慢等问题。它通过提供智能警报、自动化修复、统一仪表盘和协作工作区来实现这一目标,使团队能够从被动救火转向主动的、数据驱动的管理。
Lovable.dev 提供哪些重要的 SRE 功能?
Lovable.dev for Ops 提供智能警报、自动化修复、服务水平目标 (SLO) 跟踪和无责事后分析工具。这些功能使 SRE 团队能够专注于工程解决方案,减少平均恢复时间 (MTTR),并最终构建更具弹性的系统。
Lovable.dev 可以与现有技术堆栈集成吗?
是的,Lovable.dev 采用开放的、API 优先的方法,确保与您现有的工具生态系统无缝集成。这包括流行的监控工具(例如 Prometheus、Grafana)、警报工具(例如 PagerDuty)、通信工具(例如 Slack、Microsoft Teams)、版本控制工具(例如 GitHub)和云平台(例如 AWS、Azure、GCP)。
Lovable.dev 如何帮助扩展运营效率?
Lovable.dev for Ops 专为规模化而构建,通过集中管理、标准化的运营工作流程和新资源的自动化配置来支持组织增长。其架构旨在处理大量数据和复杂的自动化而不会降低性能,确保在您扩展时保持效率。